
어떤 항목들을 크기가 작은 순서대로 정렬 (sorting) 하고 싶다고 하면, 가장 간단한 방법은 가장 작은 항목을 그룹에서 맨 앞으로 이동시키는 것을 반복하는 것이다. 그러나 이 알고리즘은 시간 복잡도가 O(n^2) 이므로, 더 나은 알고리즘을 찾아야 한다.
제자리 정렬 (in-place sort) 은 정렬할 항목의 수에 비해 아주 작은 저장 공간을 더 사용하는 정렬 알고리즘을 뜻한다. 삽입 정렬은 주어진 원소들을 옮긴 뒤 적절한 위치에 원소를 삽입하는 연산을 반복하는데, 이로 인해 항목을 담는 공간 외에 추가로 사용될 수 있는 공간은 옮겨지는 항목이 저장되는 공간과 반복문 변수 정도에 불과하다.
안정적 정렬 (stable sort) 은 데이터 요소의 상대적인 순서를 보존한다. 데이터의 두 항목이 크기가 같을 때, 정렬 전의 위치 상태를 똑같이 유지한다. 모든 비교 정렬 (comparison sort) 문제에서 키 (key) 는 정렬 순서를 결정하는 값을 뜻하며, 대부분의 경우 비교 정렬 알고리즘은 최악의 경우 시간 복잡도가 O(n log n)보다 좋지 않다.
2차 정렬
거품 정렬
거품 정렬 (bubble sort) 은 인접한 두 항목을 비교하여 정렬하는 방식이다. 시간 복잡도는 O(n^2) 이지만 코드가 단순하며 항목이 수면 위로 거품처럼 올라오는 듯한 모습을 보이기 때문에 붙은 이름이다. 정렬 방식은 다음과 같다.
1. 리스트의 인덱스 0부터, 해당 항목과 다음 항목을 비교하며 큰 수가 오른쪽으로 가도록 재정렬한다.

2. 반복한다.

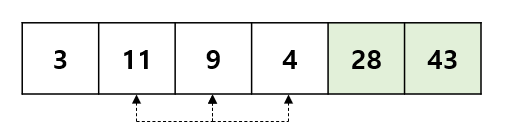

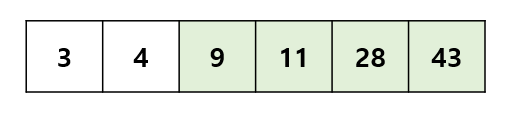

흰색은 아직 정렬이 완료되지 않는 부분, 초록색은 정렬이 완료된 부분이다. 각 정렬마다 각 인덱스를 정렬시키기 때문에, 한 정렬마다 n-1 번의 정렬을 하며, 정렬을 n-1 번 만큼 반복해야 하므로, 시간 복잡도는 O(n^2) 이다. 이를 코드로 구현하면 다음과 같다.
def bubble_sort(l): # 내 정답
length = len(l)-1
for i in range(length-1):
print(l)
for j in range(length-i):
if l[j] > l[j+1]:
l[j], l[j+1] = l[j+1], l[j]
def bubble_sort_answer_book(seq): # 책의 정답
length = len(seq) - 1
for num in range(length, 0, -1):
for i in range(num):
if seq[i] > seq[i+1]:
seq[i], seq[i+1] = seq[i+1], seq[i]
return seq
list_test_1 = [11, 3, 28, 43, 9, 4]
list_test_2 = [11, 3, 28, 43, 9, 4]
bubble_sort(list_test_1)
bubble_sort_answer_book(list_test_2)
print(list_test_1)
print(list_test_2)
결과
PS C:\Users\bumsu\Desktop\Python\DSA> & C:/Python38/python3.exe "c:/Users/bumsu/Desktop/Python/DSA/Algorithm/9. 정렬/bubble_sort.py"
[11, 3, 28, 43, 9, 4]
[3, 11, 28, 9, 4, 43]
[3, 11, 9, 4, 28, 43]
[3, 9, 4, 11, 28, 43]
[3, 4, 9, 11, 28, 43]
[3, 4, 9, 11, 28, 43]선택 정렬
선택 정렬 (selection sort) 은 먼저 리스트에서 가장 작거나 큰 항목을 찾아 첫 번째 항목과 위치를 바꾼다. 그러고 나서 그 다음 항목을 찾아 두 번째 항목과 위치를 바꾼다. 이런 식으로 리스트의 끝에 도달할 때 까지 이 과정을 반복한다. 리스트가 이미 정렬되어 있더라고 시간 복잡도는 O(n^2) 이며, 안정적이지도 않다. 정렬 방식은 다음과 같다.
1. 리스트 중 가장 작은 항목을 찾아서 정렬한다.

2. 반복한다.





흰색은 아직 정렬이 완료되지 않는 부분, 초록색은 정렬이 완료된 부분이다. 각 정렬마다 한 인덱스 씩 앞으로 정렬시키기 때문에, 한 정렬마다 n개의 항목을 탐색하며, 정렬을 n-1 번 만큼 반복해야 하므로, 시간 복잡도는 O(n^2) 이다. 이를 코드로 구현하면 다음과 같다.
def selection_sort(l): # 내 정답
length = len(l)
for i in range(length-1):
print(l)
j_min = i
for j in range(i, length):
if l[j] < l[j_min]:
j_min = j
l[i], l[j_min] = l[j_min], l[i]
def selection_sort_answer_book(seq): # 책의 정답
length = len(seq)
for i in range(length-1):
print(seq)
min_j = i
for j in range(i+1, length):
if seq[min_j] > seq[j]:
min_j = j
seq[i], seq[min_j] = seq[min_j], seq[i]
return seq
list_test_1 = [11, 3, 28, 43, 9, 4]
list_test_2 = [11, 3, 28, 43, 9, 4]
print('test 1 (book answer)')
selection_sort(list_test_1)
print(list_test_1)
print('test 2 (book answer)')
selection_sort_answer_book(list_test_2)
print(list_test_2)
결과
PS C:\Users\bumsu\Desktop\Python\DSA> & C:/Python38/python3.exe "c:/Users/bumsu/Desktop/Python/DSA/Algorithm/9. 정렬/selection_sort.py"
test 1 (book answer)
[11, 3, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 4, 28, 43, 9, 11]
[3, 4, 9, 43, 28, 11]
[3, 4, 9, 11, 28, 43]
[3, 4, 9, 11, 28, 43]
test 2 (book answer)
[11, 3, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 4, 28, 43, 9, 11]
[3, 4, 9, 43, 28, 11]
[3, 4, 9, 11, 28, 43]
[3, 4, 9, 11, 28, 43]
책의 정답과 내 정답은 거의 일치하나 책의 정답은 각 정렬마다 맨 처음 확인하는 항목은 그대로 두고 정렬하므로 실행 시간이 조금 더 단축되었다 (어차피 가장 작은 항목이라면 바꿀 필요가 없으므로). 따라서 책의 정답이 조금 더 효율적이다.
삽입 정렬
삽입 정렬 (insertion sort) 은 최선의 경우 시간 복잡도는 O(n) 이고, 평균과 최악의 경우 O(n^2) 인 간단한 정렬 알고리즘이다. 배열 맨 처음 정렬된 부분에, 정렬되지 않은 다음 항목을 삽입하는 방식이며, 데이터 크기가 작고 리스트가 이미 정렬되어 있으면 병합 정렬이나 퀵 정렬 같은 고급 알고리즘보다 성능이 더 좋다. 따라서 미리 정렬된 리스트에 새 항목을 추가할 때 쓰면 좋다. 정렬의 과정은 다음과 같다.
1. n 번째 정렬 때는 n+1 번째 인덱스 항목부터 첫 번째 항목까지 검색하며 바로 옆 항목과 비교하여 더 작은 수 (또는 큰 수) 를 왼쪽으로 보내준다.

2. 반복한다.




초록색은 정렬 중인 항목이다. 각 정렬마다 한 인덱스 씩 앞으로 정렬시키기 때문에, 한 정렬마다 최대 n개의 항목을 탐색하며, 정렬을 최대 n 번 만큼 반복해야 하므로, 평균과 최악의 시간 복잡도는 O(n^2) 이다. 그러나 마지막 인덱스에 항목을 하나 집어 넣는다고 생각했을 때, 정렬을 한번만 반복하면 되지만 n개의 항목을 탐색해야 하기 때문에, 최선의 시간 복잡도는 O(n)이다.
이를 코드로 구현하자면 다음과 같다.
def insertion_sort(l): # 내 정답
length = len(l)
for i in range(1, length, 1):
print(l)
for j in range(i, 0, -1):
if l[j] < l[j-1]:
l[j-1], l[j] = l[j], l[j-1]
print('test 1 (my answer)')
list_test_1 = [11, 3, 28, 43, 9, 4]
insertion_sort(list_test_1)
print(list_test_1)
def insertion_sort_answer_book(seq): # 책의 정답
for i in range(1, len(seq)):
print(seq)
j = i
while j > 0 and seq[j-1] > seq[j]:
seq[j-1], seq[j] = seq[j], seq[j-1]
j -= 1
return seq
def insertion_sort_rec(seq, i=None): # 책 정답, 재귀 방식, 시작 지점을 설정할 수 있음.
if i is None:
i = len(seq) - 1
if i == 0:
return i
insertion_sort_rec(seq, i-1)
j = i
while j > 0 and seq[j-1] > seq[j]:
seq[j-1], seq[j] = seq[j], seq[j-1]
j -= 1
return seq
print('test 2 (book answer)')
list_test_2 = [11, 3, 28, 43, 9, 4]
list_test_3 = [11, 3, 28, 43, 9, 4]
insertion_sort_answer_book(list_test_2)
print(list_test_2)
insertion_sort_rec(list_test_3)
print(list_test_3)
결과
PS C:\Users\bumsu\Desktop\Python\DSA> & C:/Python38/python3.exe "c:/Users/bumsu/Desktop/Python/DSA/Algorithm/9. 정렬/insertion_sort.py"
test 1 (my answer)
[11, 3, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 9, 11, 28, 43, 4]
[3, 4, 9, 11, 28, 43]
test 2 (book answer)
[11, 3, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 11, 28, 43, 9, 4]
[3, 9, 11, 28, 43, 4]
[3, 4, 9, 11, 28, 43]
[3, 4, 9, 11, 28, 43]
재귀 함수를 사용하지 않은 정렬은 내가 제시한 방식과 근본적으로 같다. 재귀 함수를 사용하는 정렬은 시작 지점을 직접 설정할 수 있다는 장점이 있다. 따라서 만약 리스트의 마지막에 항목을 추가할 때 최선의 경우로 정렬을 할 수 있어 시간을 획기적으로 줄일 수 있을 것이다.
놈 정렬
놈 정렬 (gnome sort) 은 앞으로 이동하며 잘못 정렬된 값을 찾아 올바른 위치로 값을 교환하며 다시 뒤로 이동한다. 최선의 경우 시간복잡도는 O(n) 이고, 평균과 최악의 경우 O(n^2) 인 알고리즘이다. 코드는 다음과 같다.
def gnome_sort(seq):
i = 0
while i < len(seq):
print(seq)
if i == 0 or seq[i-1] <= seq[i]:
i += 1
else:
seq[i], seq[i-1] = seq[i-1], seq[i]
i -= 1
return seq
list_test = [5, 3, 2, 4]
gnome_sort(list_test)
print(list_test)
결과
PS C:\Users\bumsu\Desktop\Python\DSA> & C:/Python38/python3.exe "c:/Users/bumsu/Desktop/Python/DSA/Algorithm/9. 정렬/gnome_sort.py"
[5, 3, 2, 4]
[5, 3, 2, 4]
[3, 5, 2, 4]
[3, 5, 2, 4]
[3, 5, 2, 4]
[3, 2, 5, 4]
[2, 3, 5, 4]
[2, 3, 5, 4]
[2, 3, 5, 4]
[2, 3, 5, 4]
[2, 3, 4, 5]
[2, 3, 4, 5]
[2, 3, 4, 5]
놈 정렬은 쉽게 말하자면 앞으로 갔다 뒤로 갔다 하며 잘못 정렬된 항목들을 재정렬시키고 다시 앞으로 갔다 뒤로 갔다 하는 방식의 정렬이다.
정렬되는 방식을 혹시 보고싶다면 아래 링크의 동영상을 보도록 하자. 살짝 불쾌한 애니메이션이긴 하지만 한눈에 이해되는 것 같다.
https://www.youtube.com/watch?v=43noNfrbEnQ
선형 정렬
카운트 정렬
카운트 정렬 (count sort) 은 작은 범위의 정수를 정렬할 때 유용하며, 숫자의 발생 횟수를 계산하는 누적 카운트를 사용한다. 누적 카운트를 갱신하여 순서대로 숫자를 직접 배치하는 방식이다. 카운트 정렬에서 각 숫자 간 간격이 크다면, 로그 선형 제한이 걸리며 비효율적이 된다. 각 숫자의 간격이 크지 않다면, 시간 복잡도는 선형인 O(n+k)다.
from collections import defaultdict
def count_sort_dict(a):
b, c = [], defaultdict(list)
for x in a:
c[x].append(x)
for k in range(min(c), max(c) + 1):
b.extend(c[k])
return b
seq = [3,5,2,6,8,1,0,3,5,6,2,5,4,1,5,3]
result = count_sort_dict(seq)
print(result)
결과
PS C:\Users\bumsu\Desktop\Python\DSA> & C:/Python38/python3.exe "c:/Users/bumsu/Desktop/Python/DSA/Algorithm/9. 정렬/count_sort.py"
[0, 1, 1, 2, 2, 3, 3, 3, 4, 5, 5, 5, 5, 6, 6, 8]
중복되는 항목이 많이 없을 경우 별로 유용하지 않을 듯 하다.
출처
파이썬 자료구조와 알고리즘 - 한빛미디어, 미아 스타인
'Python > 알고리즘 (Algorithm)' 카테고리의 다른 글
| 10-1. 검색 (Searching): 파이썬 자료구조와 알고리즘 (0) | 2020.08.09 |
|---|---|
| 9-2. 로그 선형 정렬, 고급정렬 (Log-linear Sorting, Advanced Sorting) (0) | 2020.08.07 |
| 8. 점근적 분석 (Asymptotic Analysis): 파이썬 자료구조와 알고리즘 (0) | 2020.08.04 |
| 7-2-2. 큐, 우선순위 큐, 힙, 연결 리스트 예제 (Other Types Examples): 파이썬 자료구조와 알고리즘 (0) | 2020.08.03 |
| 7-2-1. 스택 연습문제 (Stack Examples): 파이썬 자료구조와 알고리즘 (0) | 2020.08.03 |


